
Jargon Busting
High availability, fault tolerance and disaster recovery explained

Summary
A highly available system is one that aims to be online as often as possible. While downtime can still occur in a highly available system, the aim of high availability is to limit the duration of the downtime, not to completely eliminate it. A fault tolerant system is one that can operate through a fault without any downtime. Fault tolerance aims to avoid downtime completely. In a complete system failure however, high availability and fault tolerance are not sufficient. Disaster recovery describes how the system can continue to operate when the cushion of high availability and fault tolerance disappears in a system wide failure.
High availability, fault tolerance and disaster recovery are sometimes used interchangeably by architects and developers to describe a system. These three terms are, however, not the same. Understanding what they really mean will ensure you are actually able to build highly available and fault tolerant systems that can recover from a disaster.
High Availability
First, lets describe what high availability is not. High availability does not mean that the system never fails or never experiences downtime. A highly available system is simply one that aims to be online as often as possible.
Imagine we have a pizza restaurant that is open 24 hours every day for 365 days. If that restaurant only has one chef, then its availability i.e. its ability to process orders, will not be 100% since a single chef can only work for about eight hours a day with a one hour break - effectively seven hours a day, for seven days in a week. The chef can therefore only work for 49 hours in a week out of a possible 168 hours. This restaurant has an availability of 29%.
This is obviously not a high enough availability for a restaurant that wants to be open for 24 hours in a day throughout the year. How do we get a higher availability for the restaurant? Hire more chefs. If we have four chefs working six hour shifts in a day for seven days in a week, this gives us a theoretical availability of 100%.
You can never have 100% availability because of the constraints of reality. You can only approach an availability of 100% at an increasingly steep price.
This is only theoretical because it assumes no chef misses work in an entire year. This is a poor assumption as chefs can get sick, their cars can break down on the way to work or they may have to leave work early to pick up their kids. Lets say all this chef downtime adds up five hours in a year. This gives you an availability of 99.94%. How can you make the restaurant even more available? Hire standby chefs that are ready to come to the restaurant at a moments notice. But this comes at a steep price since you have to pay these chefs to wait until they are needed. What these standby chefs give you is the ability to quickly recover from not having enough chefs to meet customer orders. You can never have 100% availability because of the constraints of reality. You can only approach an availability of 100% at an increasingly steep price.
Availability is the probability that a system will be able to respond to a request.
Note that high availability has nothing to say about the quality of the pizzas or how quickly they are delivered. High availability is simply concerned with the ability of the restaurant to respond to pizza orders from customers.
Availability is the probability that a system will be able to respond to a request. The major cloud providers typically have SLAs that describe the availability of a system. Take a blob storage system for example. AWS S3 standard has an availability SLA of 99.99%. This is the same figure for Azure blob storage and Google cloud storage.
What exactly does 99.99% availability mean? It means that in any year, there is a 99.99% probability that the system will be online. An uptime of 99.99% equals a downtime of 0.01%. This is equivalent to a downtime of approximately 53 minutes - just under an hour for an entire year. How about an availability of 99.9%? Such a system would have a downtime of 0.1% which is 8.8 hours in a year. While 99.9% availability may seem high, for a bank processing payments, air traffic control system or any other critical system, such amount of downtime may simply be unacceptable.
What is the right amount of availability one should target? That depends on the requirements of the system you are building. You are obviously constrained by the availability SLAs of the cloud providers so there is limited flexibility in achieving say 99.999% availability for a blob storage system for example. And the higher the availability you want to achieve, the more expensive and complex the solution becomes.
Fault Tolerance
If a failure within a system occurs, can the system continue to operate without any disruption? If it can, then the system is fault tolerant. What is the difference between high availability and fault tolerance? With a highly available system, failures that cause downtime will occur, but rarely. And when the system is down, it cannot respond to requests. In a fault tolerant system, the system can continue to operate in spite of a failure.
Lets use the pizza restaurant as an example again. If the restaurant experiences a power outage, then no amount of chefs in the kitchen or chefs on standby will help with making pizzas for customers since the ovens need a supply of power. A backup generator that kicks in immediately a power loss is experienced makes the restaurant fault tolerant.
Another good example of this is a commercial aircraft powered by jet engines. These are built to be fault tolerant so in the event that one engine fails, the aircraft can continue to fly and land without disruption or having to fix the failed engine in flight. Helicopters or single engine aircraft on the other hand are not fault tolerant. A failure of the engine means the aircraft cannot fly. Such failures are usually catastrophic and partly explain the higher rate of helicopter and single engine aircraft crashes compared to dual engine aircraft.
Disaster Recovery
If the scale of the system failure is so large that the high availability and fault tolerance of the system are effectively neutralised, can the system continue to operate?
Lets go back to the restaurant example. If a fire, flood or any other disaster befalls your pizza restaurant, how can you continue to make pizzas for your customers? This is a somewhat facetious example since in the event of a fire, worrying about customer orders is not the main priority, but the logic of the example still holds. In this instance, high availability is of no help. Having an infinite number of chefs in the kitchen or on standby in a restaurant engulfed in flames = no pizzas for customers. Fault tolerance is also of no help. A backup generator is useless for the appliances it is meant to power if they have been destroyed. The only way the system (restaurant) can continue to operate is by routing orders to another nearby restaurant unaffected by the fire. Disaster recovery is a proactive plan of action that details how to recover after a disaster has happened.
Bringing it All Together
Now, lets look at a single architecture that is simultaneously highly available, fault tolerant and has built in disaster recovery.
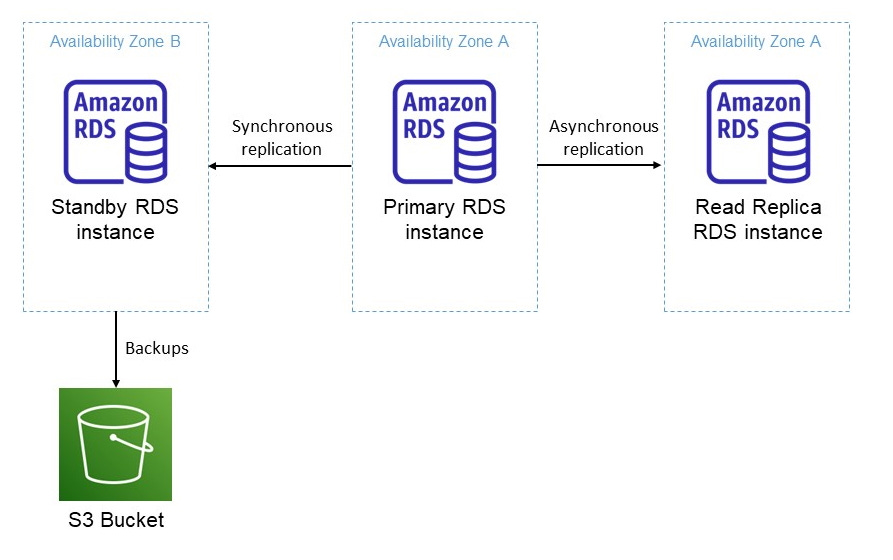
The architecture above shows a multi-AZ RDS deployment. It shows an RDS database with a standby instance in a separate AZ, a single read-only replica and an S3 bucket used to store backups of the database on a daily basis. RDS is a fully managed DB as a service offering from AWS where AWS manages the underlying hardware, software and application of the DB. More information here on AWS RDS and availability zones (AZs)
The primary RDS instance in AZ A synchronously replicates its data to the standby instance in AZ B. With synchronous replication, the primary instance waits until the standby has received the latest write operation before the transaction is recorded as successful. This ensures that both databases have identical information i.e. they are consistent, admittedly at the expense of increased transaction latency. The primary and standby instances are in an active-passive configuration; only the primary receives read and write request. The job of the standby is to simply take over as the primary in the event of a failure of the primary instance. The time it takes to failover from the primary to the standby instance is called the Recovery Time Objective (RTO). The RTO simply describes how long it takes to recover from a failure. In this case, the failover time for RDS in a multi-AZ configuration is currently between 1-2 minutes.
The standby instance has one purpose - to increase the availability of the system. If the primary instance fails, or if the entire AZ A goes down, the standby instance in a separate AZ will be promoted to the primary and this failover process takes 1-2 minutes. That is 1-2 minutes of downtime. Recall that high availability is not about preventing downtime, but simply reducing it. Without a standby instance, there is a high probability that downtime will exceed the 1-2 mins it takes to recover with a standby instance.
Note that the standby instance does not help with fault tolerance since the failure of the primary will still lead to downtime. To eliminate downtime, you need a configuration that involves no failover. This is a job for read-only replicas. These are asynchronously replicated copies of the primary instance. Writes are only made to the primary instance; read replicas are, as the name imply, read only.
Such an approach is ideal for read heavy application since read replicas can remove the additional burden of read requests from the primary instance. In asynchronous replication, writes to a primary instance do not wait for a response from the read-only replica before the transaction is recorded as a success. This means that, for a time, data across the primary and read replica may not be identical (inconsistent) after a write to the primary. This eventual consistency (a topic for another article) is a drawback of asynchronous replication. The benefit of asynchronous replication is that it does not wait for the read replica to respond before the transaction is recorded as a success. This is important because if the read replica is down or there is a network failure, the primary can still accept subsequent writes without waiting for a response from the read replica confirming that the previous write was successfully replicated. The architecture above has two replicas, one synchronous and the other asynchronous. If all replicas are synchronous, then a failure in the standby replica or the read only replica, or even a network failure brings the entire cluster down - a fragile design that exposes the entire system to failure if a single component fails. Having some replicas that are synchronous and others that are asynchronous improves the fault tolerance of the system.
Where else does fault tolerance come in? Like a an aircraft with two jet engines that provide thrust, a read replica and a primary can work together simultaneously; with the primary instance processing writes and the read replica responding to read requests. Failure of the primary instance has no effect on the read replicas ability to respond to read requests. There is no downtime for reads since only the read replica responds to reads. How about writes? The read replica can be promoted to a primary, although with RDS, this is currently a manual process.
With the architecture above, disaster recovery can be achieved in two ways. There is no constraint to limit disaster recovery to only one approach so both can be used at the same time. And in fact, the more approaches you have, the better since this provides extra redundancy. This of course has to ultimately be weighed against costs as implementing disaster recovery strategies can be expensive.
The first method is through automatic backups. Backups are taken from the standby instance, preventing performance degradation of the primary instance that has to serve writes (and reads if not configured with a read replica). Since there is synchronous replication between the primary and the standby, we have a guarantee that the standby is an up to date copy of the primary, therefore ideal to take backups from. With RDS, backups are taken on a fixed schedule once a day (specified by you) and stored in an S3 bucket. Since this is an entirely separate component, any RDS related system wide failures will not affect the durability of the backups. With backups, a loss of the primary, standby and read-replicas does not equal a permanent loss of data. Backups can then be used to restore the database to a new DB instance.
The second method is to promote the read-only replica to a standalone instance if the primary instance fails. The read replica can be configured in another AWS region so if there is a disaster on a regional scale where multiple AZs are down, a cross regional read replica will ensure that another instance is available in a different AWS region to serve read and write requests. This is analogous to diverting orders to another restaurant in the event of a fire.
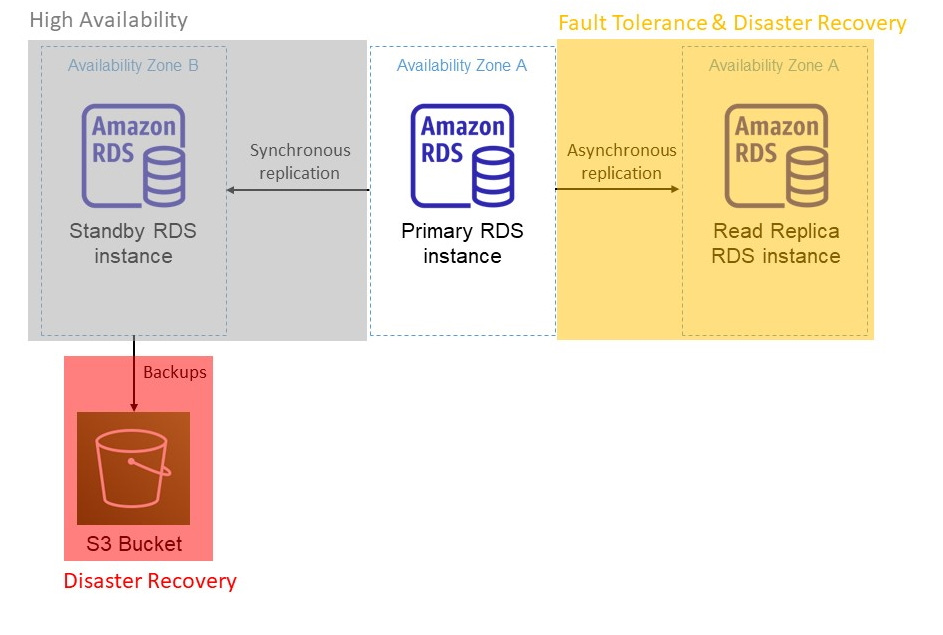
Knowing the difference between high availability, fault tolerance and disaster recovery is important because it ensures you are building the correct architecture based on customer needs. Over engineering a solution by providing disaster recovery when all that is required is high availability or fault tolerance is often an expensive and complex exercise. On the other hand, under engineering a solution by only providing high availability when fault tolerance is required can lead to severe consequences for some critical systems that cannot afford any downtime.
Your articles are simply awesome. I suggest you write more articles on Databases in depth - Replication, Partitioning, Sharding, Gossip Protocols, etc.