
How Does AWS Route 53 Work
DNS and AWS Route 53 routing policies Explained

Summary
Route 53 is a DNS (Domain Name System) managed by AWS. DNS is global distributed database that maps domain names (like google.com) to IP addresses that your browser uses to communicate with. Route 53 also has simple and complex routing policies that can route client request based on several preferences, like minimising latencies between clients and servers and ensuring requests are only sent to healthy servers, among others. These policies allow you to create architectures that span the globe and ensure requests are routed to the appropriate resources.
Route 53 is Amazon’s managed DNS. Cloudflare and GoDaddy are other popular DNS providers. But what exactly is DNS?
DNS is like the yellow pages of the internet. The yellow pages are a telephone directory where businesses and their respective telephone numbers are alphabetically listed and published in the form of a large book. The yellow pages have one purpose - to map a business name to its telephone number so people could call the business if they so wished.

Perhaps a more apt analogy for the younger readers is the phonebook on your mobile phone. At a minimum, a phonebook will store the contact name and telephone numbers of businesses and individuals. Its fundamentally the same as the yellow pages in that it maps a contact to one or more telephone numbers.
If you wanted to call your mum, you would go through your contacts, select “mum” and hit “call”.
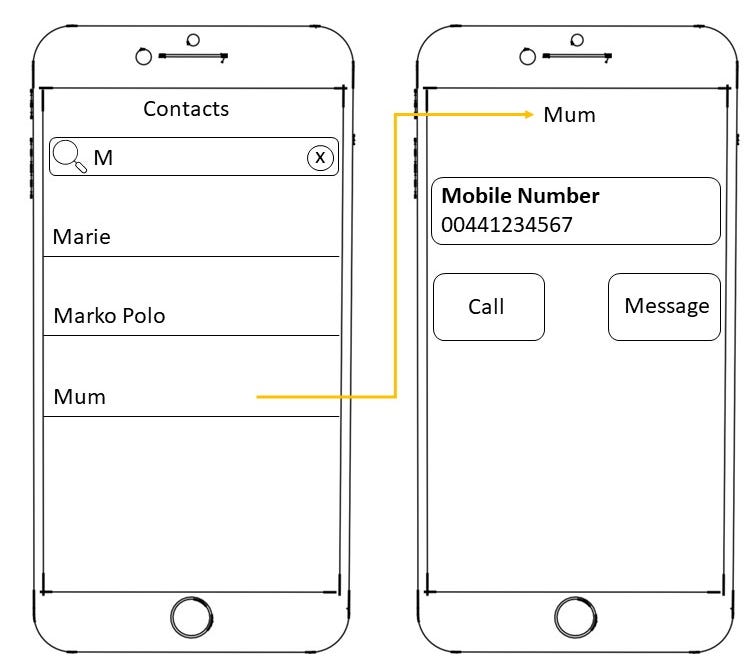
Your mobile phone then calls the number mapped to mum. This is all obvious of course. “Mum” is not something your phone can physically connect to in order to establish a call. It is the number that is mapped to the contact which the phone uses to establish a connection with another phone.
DNS works in a similar way. It is like a global telephone directory for the internet that maps domains (like google.com) to an IP address. This analogy is somewhat flawed however, since different people will have “mum” stored on their phones, each having different numbers. While contact names are not globally unique unlike domain names, the logic still holds; DNS maps domain names to IP addresses, similar to how a phonebook maps contact names to telephone numbers.
When you type in google.com in your browser, it requires the associated IP address for that domain because google.com is not a physical address on the internet. The image below shows a highly abstracted version of what happens when you try to visit google.com.
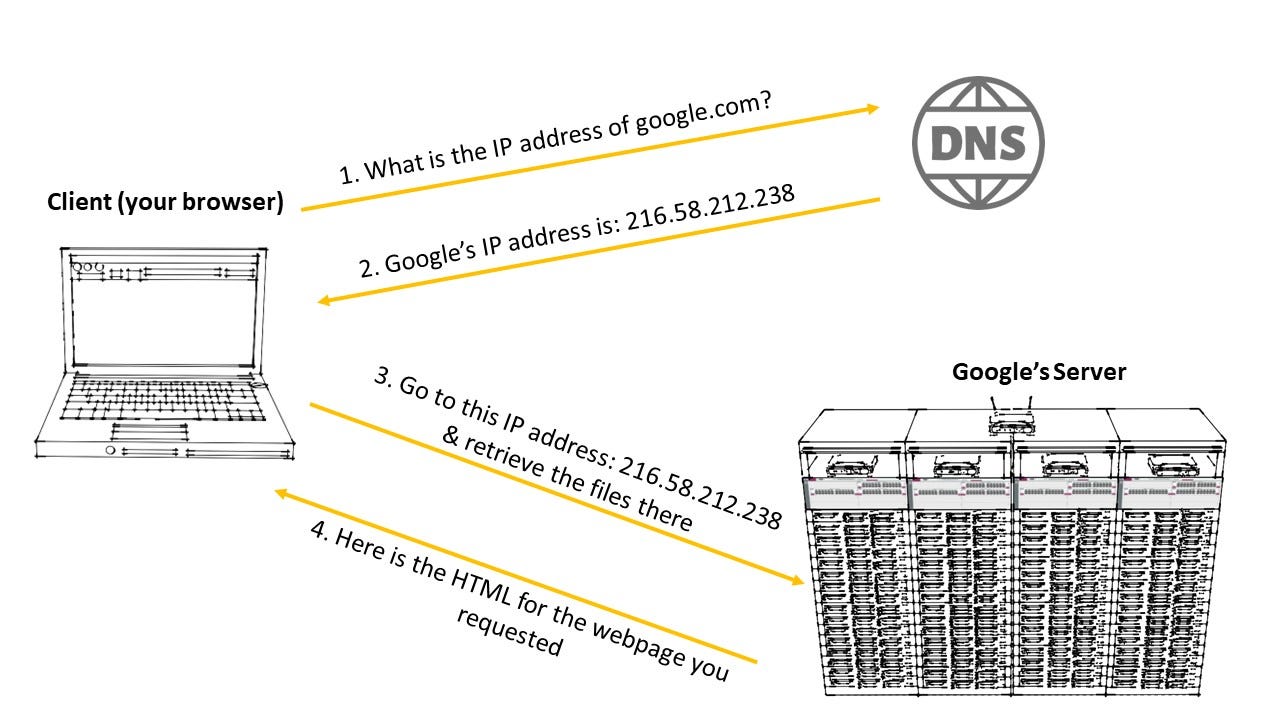
The DNS Inverted Tree
Route 53, which is Amazon’s managed DNS service, is a distributed database. It is also very large. Just how large exactly? IP addresses come in two classes - IPv4 and IPv6. While this post will not cover the differences between IPv4 & IPv6, it is useful to understand the number of possible IP address. IPv4 has 2^32 IP addresses (about 4.3 billion). With IPv6, there are 2^128 IP addresses (about 340 trillion trillion trillion). This is more than the number of stars in the observable universe. How exactly can you find the right IP address for google.com without crawling through every possible IP address to find a match? To understand this, we first need to understand the structure of a URL.
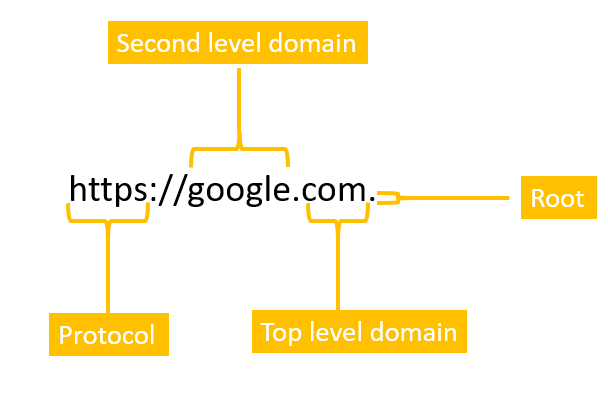
The URL above is read from the right to the left, starting with the root. The root is just a full stop that you don’t need to type - your browser invisibly adds it on your behalf.
The information that contains the IP address we are looking for is stored in a name server as a zone file (think of it as a database). This zone file has a DNS record that translates google.com to its IP address.
Recall that the URL is read from right to left. If you look back on the image that shows the URL structure, the first query for the IP address of google.com is sent to the DNS root zone. The root name server then points to the IP address of the .com name server since we are trying to visit a domain that has a top level domain of .com. The name server for the .com zone will then point at the google.com name server which will have a entry there for the IP address of google.com. This IP address is then returned to your browser which then sends a request to google.com to load the page.
The DNS hierarchy looks like an inverted tree, and getting the IP address of google.com starts at the DNS root, then to the top level domain and finally the second level domain.

Now that DNS has been explained, where exactly does Route 53 come into the picture? Let’s say you want to create your own domain called 123.com. What happens when you register 123.com with Route 53?
Route 53 checks with the top level domain (.com in this instance) to see if 123.com already exists. Let us assume this domain is not already registered since domains need to be globally unique.
Route 53 creates a zone file for the domain. Recall that this zone file is just a database that contains DNS information. An example of a zone file and an explanation of its structure can be seen here.
Route 53 creates name servers and stores this zone file on them. The name servers are globally distributed to ensure resilience and are managed by AWS on your behalf.
Route 53 then adds the name server records to the the top level domain name servers (.com in this instance) which is managed by Verisign. This will enable the .com name servers to point at the 123.com name servers you just created with Route 53. Future visitors to your newly created domain will then have to go through the DNS inverted tree hierarchy to find the IP address for 123.com, stored on the name servers that Route 53 manages for you .
Routing Policies
Route 53 can however do much more than that just help you register domains and manage the name servers that stores the zone files for your domain. What if you, as the owner of 123.com, are trying to route traffic to your website from visitors in different parts of the world and you want to minimise latency? Or if you want to show different content to people based on which country they are in? In come routing policies.
Simple Routing
This policy is relatively straightforward. It maps a domain name to a single record. This record can have one or more IP addresses (which can reference one or more web servers of a website for example). If a record has multiple IP addresses, Route 53 returns all of these to the client (your browser in this example). The client chooses one of these IP addresses and connects to the server. Simple routing has no health checks in place, so if any of the servers are down/unhealthy, the client does not get a response.
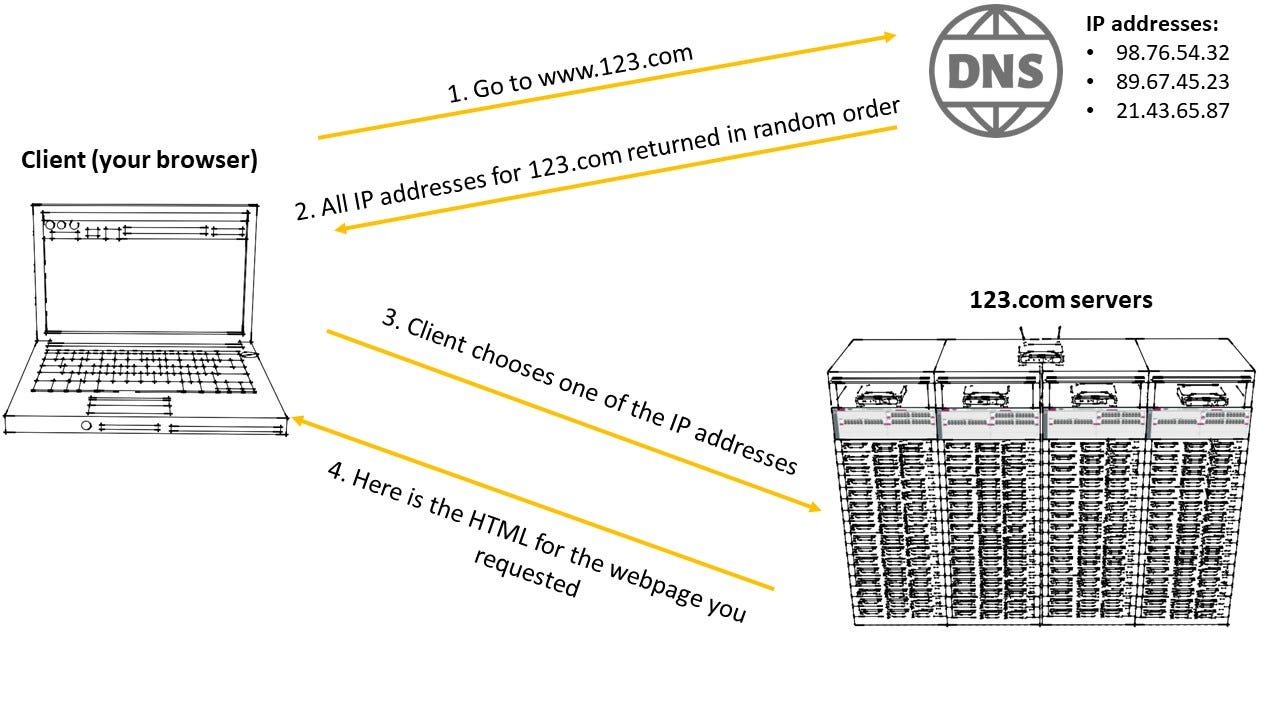
This is analogous to searching for the phone number of a restaurant called “Pizza 123” (the record) which may have different numbers listed (the IP addresses) for the same branch . You then call one of these numbers and are connected to the restaurant.

What happens if one or all of the numbers listed under Pizza 123 are not working, or the restaurant is closed? Since simple routing has no health checks in place, the customers call will go unanswered and there is no intelligent way of routing the call somewhere else. If you need a way of dealing with failures, another routing policy is required.
Failover Routing
Traffic is only routed to a record if it is healthy, otherwise it is routed to another record. You have a primary and standby record, which can both have the same name (so both records can be www.123.com). Traffic is only routed to the primary record and health checks are used to confirm that the primary record is healthy. If it becomes unhealthy, traffic is routed to the standby. These health checks consists of TCP and HTTP/HTTPS checks to ensure that the server is responding to requests in a timely fashion.
The diagram below shows what happens if the primary record is healthy.
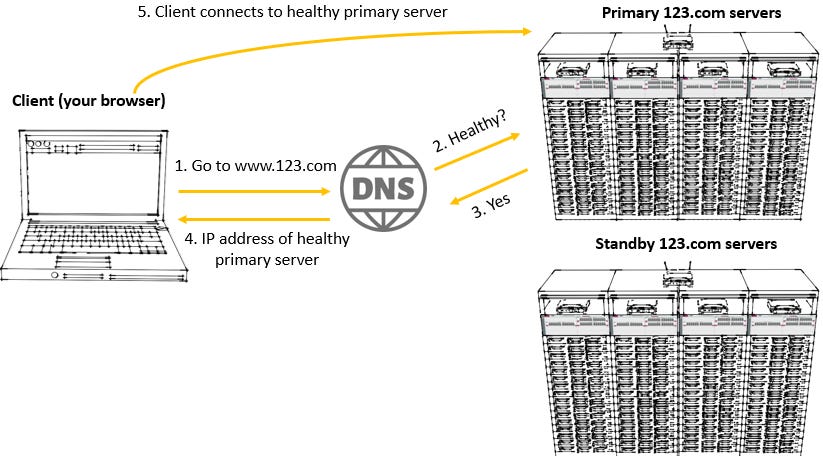
If the primary record is unhealthy, Route 53 sends the client the IP address of the standby record.

Failover routing is much more intelligent than simple routing. The yellow pages analogue is no longer valid for this type of routing since a static directory cannot be updated in real time to account for the fact that a restaurant branch is not open for example. A static directory also knows nothing about the client making the request or the server responding to the request. The complex routing strategies provided by Route 53 need to know information about the client making the request and the server responding to the request. A more apt analogy for Route 53 is an intelligent call centre agent. This agent can connect you to any business you want to contact, and in this case, it can check that the restaurant is still open and the phone numbers are working before connecting you. If it isn’t, it will divert your call to another branch that is open and has working phones.

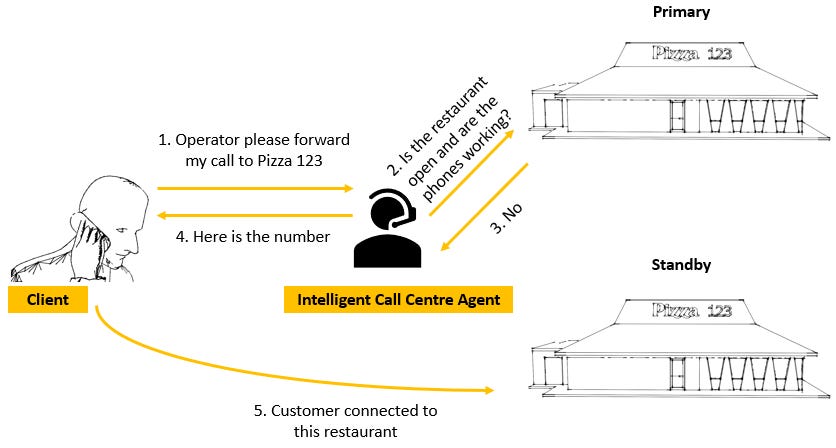
What is the benefit of this over simple routing? Failover routing gives you high availability and disaster recovery. Recall that high availability is simply about reducing downtime while disaster recovery allows you to quickly recover from a system wide failure. An active-passive architecture gives you high availability and a way to quickly recover from a disaster.
Multi Value Routing
This is similar to simple routing but with one difference - Route 53 does a health check on the records and only returns healthy records to the client. The client then uses one of these to connect to the server. Multi value routing is superior to simple routing because multiple records plus a health check to only send back healthy records improves the availability of the solution by reducing downtime.
Weighted Routing
This routing policy does a job similar to a load balancer in that it splits incoming traffic into different different resources based on weights specified by you. Say you have two records called 123.com each with a separate IP addresses. With weighted routing, you can specify a weight for each record as shown below.
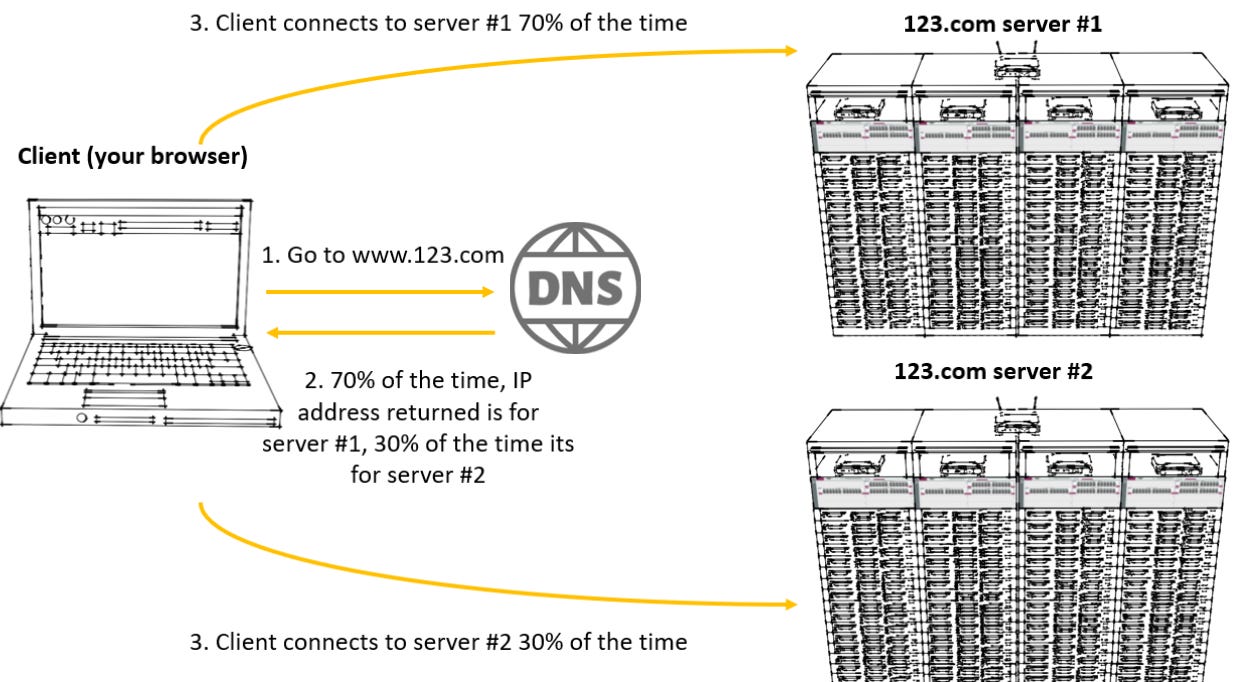
This routing policy is ideal for testing new versions of a software by only sending a small percentage of the traffic to servers hosting the new version.
Latency Routing
This is used when your application is hosted on multiple AWS regions. This policy routes traffic with the aim of minimising latency between the client and the server. Say you have two records with the same name (123.com) with each record having an IP address associated with it. With latency routing, AWS maintains a database of latencies between different source (client) and target (server) regions and will return the IP address to the client that has the lowest predicted latency between the client and the server.
If the client is from Manchester, England, then chances are highly likely that the latency between Manchester and London will be less than between Manchester and Northern Virginia. This is illustrated below.

Latencies between regions are however not constants. Latency routing is based on measurements over a period of time, which are subject to change. So if there is a prolonged increase in latency between Manchester and London compared to Manchester and Norther Virginia, traffic from Manchester will be routed to Northern Virginia instead.
Drawing on the restaurant analogy, if a customer calls the intelligent call centre agent who has been instructed to route orders based on minimising the food delivery times, the agent will figure out where the order is coming from and which restaurant is most likely to deliver in the shortest amount of time. As intelligent as this call centre agent is, he cannot predict the future. He can only look to the past to see that for orders coming from a particular region, minimising delivery time is best achieved by sending the order to a restaurant that has a history of making rapid deliveries to that region.
Geolocation Routing
This policy routes requests to records based on the geographic location of users. While this sounds similar to latency routing, the two are different. Latency routing is about routing requests with the constraint of limiting latencies between the client and the server. While clients and servers in the same region are likely to have lower latencies between themselves compared to clients and servers in different regions, this is not necessarily always the case.
Records are tagged with a location - continent, country or specific states (for the USA). When a request is made, an IP check is used to confirm the geographic location of the client. The IP address of the record sent back to the client is the one that matches the clients state (for US clients only), country or continent, in that order. If the client IP address does not match any of these locations, it is routed to a default location which is defined by you.
Consider a client making a request from Manchester, England for a website that has multiple records across three different regions - Europe (London) region, Europe (Paris) region and US East (Northern Virginia) region. In this case, Route 53 will return the record in the region that matches the geographic location of the user - so Europe (London) in this instance.

A popular use case for geolocation routing is to restrict access to content based on the location of users. This is popular with online retailers that will typically route requests to a version of the website that matches the language and currency of the client - so a visitor from the UK will be routed to the UK site where prices are quoted in Pounds Sterling and the website is in English while French visitors will be routed to the French site where prices are in Euros and the website is in French.
Geoproximity Routing
This policy routes requests based on the shortest distance between a client and the record. Records can be tagged based on the AWS region they are in or based on longitude and latitude coordinates.
At first, this seems similar to geolocation routing, but there is a difference. With geoproximity routing, requests will be routed based on the shortest distance between the client and the server. If the servers are in London and Northern Virginia regions and the client request is coming from Spain, the request will be routed to London since this is in closer proximity to Spain.
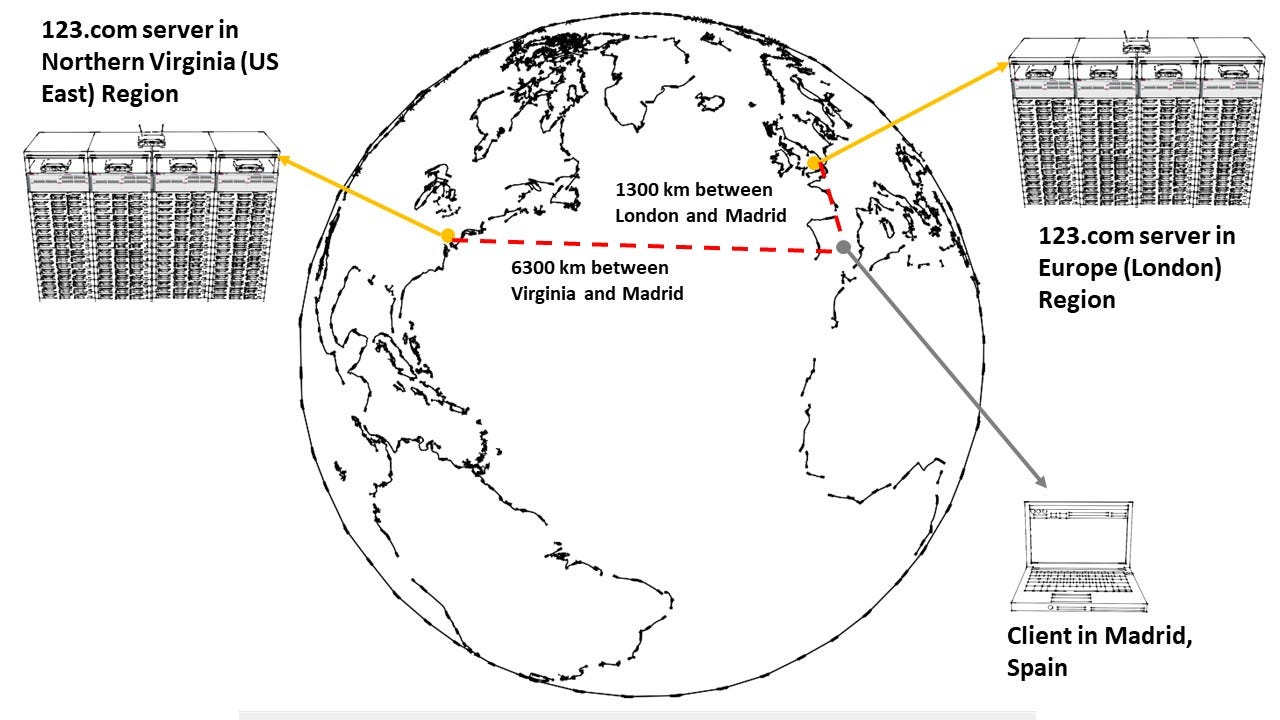
However, geoproximity routing allows for a bias (numerical value between -99 and +99).
The positive bias formula is:
Biased Distance = Actual distance * (1-(bias/100))
If we have a bias of +90 for the Northern Virginia (US East) region, then the biased distance between the client and the servers in Northern Virgina is reduced to just 630 km, compared to the actual distance of 6300 km between Northern Virginia and Madrid. This is shorter than the distance between Madrid and London. Traffic from Madrid will now be routed to Northern Virginia.
What is the use case for geoproximity routing? If servers in the the Europe (London) region are overwhelmed with requests from nearby countries, or if the servers in this region are currently undergoing maintenance, or the servers in Northern Virginia simply have more capacity allocated, requests can be routed to the servers in Northern Virginia by applying a bias towards this region. A positive bias applied to a region effectively shrinks the distance between the region and the location of the clients.
Geoproximity routing gives you additional flexibility to route requests based on where requests are coming from while also giving you the ability to route traffic to regions that may be underutilised. By applying a bias, you can dynamically control where requests are sent and are no longer constrained by the geographic distance between the client and the server.