
Synchronous and Asynchronous Design Patterns
Benefits, flaws and architectural patterns

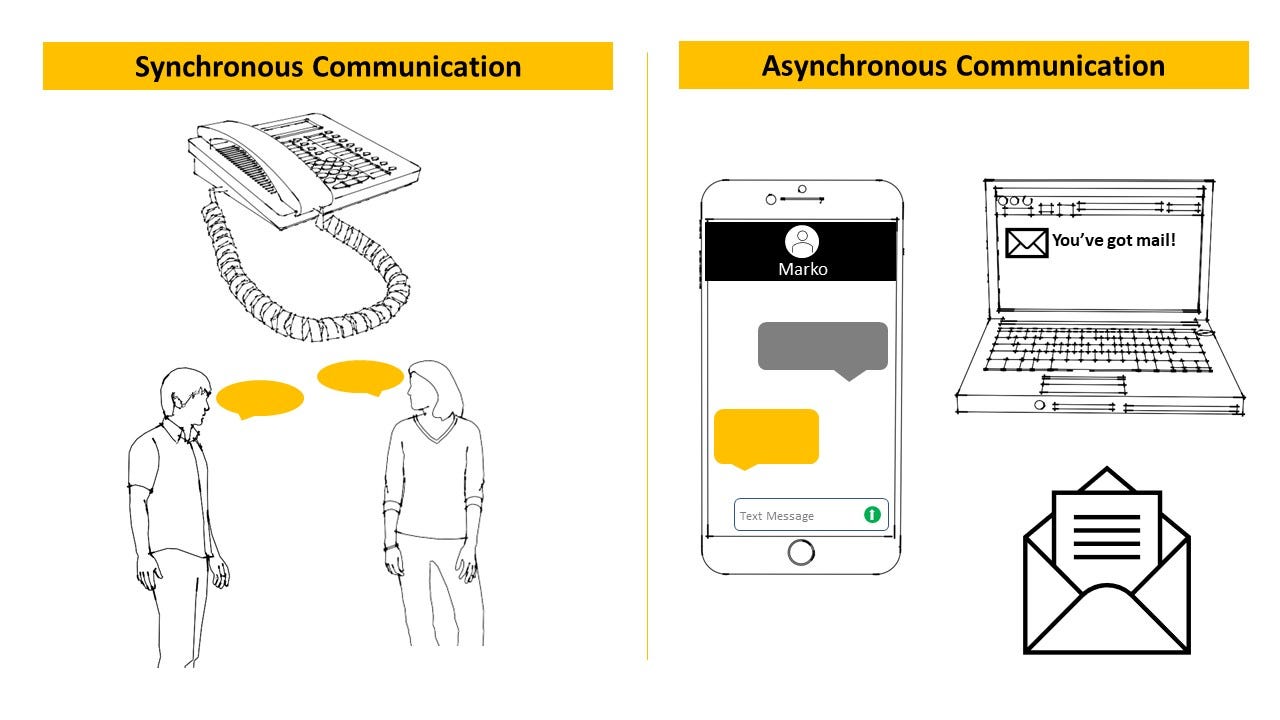
Communication is like tango - they both require at least two people to make it work. Bad jokes aside, communication can, broadly speaking, either be synchronous or asynchronous.
Synchronous communication requires the two parties to be available at the same time. A telephone call or people chatting face to face is an example of synchronous communication. If one of the parties drops the phone or walks away from the conversation, messages can no longer be exchanged and communication is effectively stopped. Synchronous communication follows a request-response pattern. After a message is sent, the sender waits for a response before doing anything else.
Asynchronous communication does not require the two parties to be available at the same time. Sending someone a text does not require the recipient’s phone to be available to receive the message. At the time of sending the text, the recipient’s phone may be switched off or may not have signal. This has no effect on the sent message because once the phone becomes available again, the recipient receives the message. The same goes with sending an email or a letter through the postal service. Asynchronous communication does not require the recipient to be immediately available to receive the message. After a message is sent, the sender does not wait for a response.
The main benefit of asynchronous communication is that it decouples components in a system. What exactly is meant by decoupling and why is that important?
Imagine going to a popular pizza restaurant on the weekend. If the restaurant is full, guests will typically form a queue outside the restaurant and wait to be seated once a table is available. A queue decouples (or separates) the mismatch in capacity between the available space in the restaurant and new guests that want to get into the restaurant. Without a queue, the restaurant will simply close its doors once it is full. This would leave the restaurant poorer and guests unhappy.

Once in the restaurant, customers place orders for pizzas. The orders are also queued by the chef since he can only make so many pizzas at the same time.
Queues are a great example of how asynchronous communication is achieved in the real world. By placing people in a queue, you remove the requirement that the two entities (people and tables) need to be available at the same time. By placing orders in a queue, you similarly remove the requirement that there needs to be a chef available to immediately process the order. Once a chef becomes available, he can simply pick up the order from a queue and make the food.
This article will cover two architectural patterns explaining how synchronous and asynchronous communication is achieved in database replication and messaging queues.
Architectural Patterns
Synchronous and Asynchronous Database Replication with AWS RDS
RDS is a fully managed, relational database solution from AWS. It supports several engines (MySQL, MariaDB, Oracle, PostgresSQL, Aurora). The great thing about running a database on RDS versus self hosting your database or hosting it on an EC2 instance comes down to one word - abstraction. RDS abstracts away most of the operational overhead required to run a database by managing the underlying hardware, software and database application for you. This means complex and time consuming operations like implementing OS patching, automatic backups and replication is all handled by AWS.
The feature of interest in this case is replication. AWS RDS has two types of replicas - standby replicas and read replicas. The architecture below shows a multi-AZ RDS deployment. It shows an RDS database with a standby instance in a separate AZ and a read replica.

The primary and standby instances are in an active-passive configuration; only the primary receives read and write requests. The job of the standby is to simply take over as the primary in the event of a failure of the primary instance.
The primary RDS instance in AZ A synchronously replicates its data to the standby instance in AZ B. With synchronous replication, the primary instance waits until the standby has received the latest write operation before the transaction is recorded as successful. This ensures that both databases have identical information i.e. they are in synch. The benefit of synchronous replication is that it ensures strong consistency i.e. after writing to the primary instance, you have certainty that subsequent reads from the primary or standby instance (if the primary fails) will have the up-to-date write. Synchronous communication is clearly not all bad.
The drawback of synchronous replication is that it is not fault tolerant. What happens if the standby instance does not respond to the write? This could happen for a multitude of reasons - availability zone failure in AZ B where the standby instance is hosted, instance failure or network failure. If the standby instance does not confirm it has received the write operation replicated from the primary instance, then the write is considered to have failed. This failure blocks subsequent writes to the primary instance.
Now let’s consider the asynchronous alternative. RDS performs asynchronous replication to the read replicas. These replicas are for reads only, all writes are still made to the primary instance. Read replicas allow you to scale a read heavy database.
In asynchronous replication, writes to a primary instance do not wait for a response from the read replica before the transaction is recorded as a success. This means that, for a time, data across the primary and read replica may not be identical after a write to the primary.
The benefit of asynchronous replication is that it does not wait for the read replica to respond before the transaction is recorded as a success. This is important because if the read replica is down or there is a network failure, the primary can still accept subsequent writes without waiting for a response from the read replica confirming that the previous write was successfully replicated. This decoupling between the primary instance and the read replica is the main benefit of asynchronous replication. It creates a fault tolerant system that does not completely fail if there is a single component or network failure.
So, which is better for database replication, synchronous or asynchronous communication? The answer is, unfortunately, the unsatisfying and dreaded “it depends”. If your application requires strongly consistent reads, then synchronous replication is preferred as it ensures strong consistency. If the database is used for a critical application that cannot sustain any downtime, fault tolerance takes precedence and asynchronous replication is the way to go.
Messaging Queues
With AWS RDS, you have a choice to have a synchronous standby database instance, an asynchronous read replica or both. However, what if you have components in an architecture that that by default don’t give you the choice to implement asynchronous communication?
Imagine you have the architecture below. The components are tightly coupled and hence, not fault tolerant.

Let’s say the producer is an EC2 instance running an application that sends some JSON files every minute to another EC2 instance - the consumer.
What happens to the messages if there is a network failure or the consumer EC2 instance fails? How can you decouple the architecture and make it fault tolerant to network and instance failures? In come messaging queues. Popular options for message queues include RabbitMQ, ActiveMQ, Apache Kafka and AWS SQS. We shall focus on AWS SQS for now.
SQS stands for Simple Queue Service. It is a fully managed, highly available, distributed queuing system. In plain English, this simply mean that AWS abstracts away the infrastructure and operational issues of running SQS. You don’t have to worry about managing the underlying infrastructure, replication and resilience as the SQS servers are distributed within an AWS region for high availability by default.
If we placed a queue in front of the consumer instance, the JSON messages will be persisted in that queue until they are processed by the consumer.
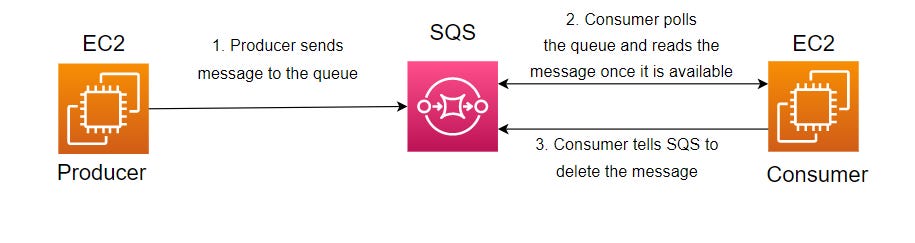
The consumer EC2 instance can then poll the queue i.e. intermittently check if there are any messages for it to consume. Once the message has been received and processed by the consumer, it will delete the message from the queue. This final step is an important feature of SQS as it ensures fault tolerance. Messages picked up from a queue are temporarily hidden for a period of time so that the consumer does not pick up the same message more than once. SQS has a visibility timeout setting (0 seconds - 12 hours as of writing) which is how long the messages are hidden before they reappear in the queue. This visibility timeout imparts fault tolerance to the system because it ensures that messages are not lost if the consumer fails. Messages re-appear after the visibility timeout expires, allowing the consumer to pick it up and reprocess again. Messages are only removed from the queue if they are explicitly deleted by the consumer i.e. when they have been processed and are no longer needed.
Adding queues to an architecture is an easy and scalable way to decouple components and make the system fault tolerant.
“There are no solutions. There are only trade-offs” - Thomas Sowell
Choosing between synchronous and asynchronous communication patterns is all about trade-offs. Synchronous communication is ideal for database replication where strongly consistent reads are required. This however comes at the cost of a tightly coupled architecture with no fault tolerance. Asynchronous communication is ideal for loosely coupled, fault tolerant architectures.