
Auto Scaling & Load Balancing Explained
A guide to designing highly available and scalable architectures

While auto scaling and load balancing are two separate technologies, they are often implemented simultaneously. In the architectural wild, one rarely exists without the other as they complement each other and work together to handle unpredictable changes in demand.
This article will explain how auto scaling and load balancing work and why it is important to consider in your designs. It will also go through example architectures showing auto scaling and load balancing in action.
Auto scaling Explained
What is it
Auto scaling, as its name implies, is simply a way to automatically scale your compute instances. With most cloud providers like AWS, GCP and Azure, you select scaling policies that define how it will add or remove instances. Scaling policies are simply rules that say how much you should increase or decrease the number of instances based on some predefined metric. Scaling policies can be dynamic, for example, by adding new instances based on CPU utilisation of the existing instances. Scaling policies can also be based on a schedule i.e. based on specific times of the day or the week when you anticipate higher or lower demand.
Dynamic Scaling
Dynamic scaling is ideal for when there is a large fluctuation of demand at unknown and unpredictable times. You know there may be a sudden surge or drop in demand on your instances, you just don’t know when.
Using a restaurant analogy, an instance can be thought of as a chef doing the work of converting orders into meals. If you only have three chefs and don’t have large fluctuations in demand throughout the day or week, you have nothing to worry about.
However, if your restaurant had a sale that was more popular than anticipated, or a large party of tourists were to suddenly descend upon the restaurant, how would you cope? What if you could add more chefs on the fly immediately when needed? This is how dynamic auto scaling works. Dynamic scaling will cause chefs to spontaneously appear in the kitchen, ready to transform orders into delicious meals, based on a predefined metric that you can choose to measure how overworked the chefs are. i.e. how much they are struggling to fulfil current orders.
Remember that these scaling policies are simply rules. These rules can be very simple, like:
if CPU utilisation is > 50%, add one more instance and If CPU utilisation is <50% remove an instance.
These rules can also be more complex.
With AWS and GCP for example, you can set a target tracking metric that will monitor the CPU performance of your scaling group and add or remove instances so that that the average CPU utilisation approximately matches your desired setting. If you specify that you want the average CPU utilisation of your scaling group to be at 60%, instances will be added or removed as required to approximately meet that target.
Using CPU utilisation to trigger a scaling action is one of the most popular patterns. However, CPU utilisation is not the only metric you can use to scale. In some ways, it can actually be suboptimal to use CPU utilisation, especially if you want even more responsive scaling. What if you could track another metric that anticipates the increase in CPU utilisation so you don’t have to wait for the inevitable increase in the CPU utilisation of your instances before a scaling action is triggered?
With GCP for example, if you have an HTTP load balancer in front of your instances, you can configure your scaling to be triggered based on the number of requests hitting your load balancer. Similarly with AWS, if you have an SQS queue in front of your instances, you can scale based on the number of messages in the queue. In both of these examples, something else anticipates a likely increase in future CPU utilisation, so setting a scaling action to be triggered based on this is a way of creating more responsive scaling. Bringing back our restaurant analogy, this would be like calling in more chefs to the kitchen once you see a large queue outside the restaurant. This is a more responsive way of dealing with a sudden surge in demand compared to waiting until your chefs are overwhelmed with orders.
Scheduled Scaling
Scheduled scaling is ideal for when there is a large fluctuation in demand at known times.
Using the restaurant analogy again, your scaling policy can be based on a schedule. So for example, if you know evenings and weekends are busier than mornings and weekdays, your scaling policy will ensure that there are more chefs during periods of higher expected demand.
With AWS and GCP, you can set a scheduled scaling policy to add or remove instances at specific times.
Why use it
Auto scaling solves the age old problem of capacity planning. Trying to accurately forecast how much compute will be required in the future is fraught with errors. Too little capacity and your website is down during periods of high demand, costing you money and reputation. Too much capacity and you are paying for unused instances.
Capacity planning is fundamentally a forecasting problem. And humans are not great at accurately forecasting the future. Before cloud providers like AWS, GCP and Azure existed, companies needed to plan capacity based on expected future demand. This planning process was often just disguised guesswork. You had to pay upfront for servers and hope you didn’t significantly under or over estimate how many servers you needed.
The problem with forecasting arises because we have a misguided faith in the precise measurement of the unknowable future. Humans have been making inaccurate forecasts for a long time. As far back as 600 BC, the Greek philosopher, Thales, was so intent on counting the stars that he kept falling into potholes on the road.
Some things are fundamentally unknowable, and that is ok. Auto scaling removes the need to accurately forecast future demand since you can automatically increase or decrease the number of instances you have based on your scaling policy.
By using auto scaling, you get to improve the resilience of your architecture and reduce costs. These are the two main reasons to use auto scaling in your designs.
Improve Resilience
Being able to automatically and immediately increase the number of instances in response to growing demand reduces the chances that your instances are under excessive load and at risk of poor performance. This improves the resilience of you architecture.
Auto scaling is, however, not only about scaling. It can also be used to maintain a set number of instances. This is a great way of creating self healing architectures. With AWS, you can set your minimum, maximum and desired number of compute instances, without any scaling policy. AWS will simply attempt to maintain the desired number of instances specified by you. So if you set the min, max and desired all equal to one, AWS will maintain one instance for you. If this instance fails, another will be automatically created to replace the failed instance to restore your desired capacity. This is a cheap and easy way of ensuring high availability without having multiple instances in different availability zones.

Self healing in action, figuratively The ability to create self healing architectures is a really strong argument to almost always place your instances in an auto scaling group. AWS and GCP do not, as of writing, charge you for the privilege of using auto scaling. You only pay for the underlying infrastructure that is created to support your instances. So, even if there is no requirement to be able to scale instances based on the demand thrown at them, having instances in an auto scaling group is a cheap and easy way of creating a self healing architecture.
Reduce Cost
Previous examples have been about scaling up the number of instances to meet higher demand. However, equally as important is the ability to scale down during periods of lower demand. Auto scaling allows you to do this using scheduled or dynamic scaling policies. This is a great way of ensuring that you are not paying for more than you need to.

Load Balancing Explained
What is it
Load balancers accept connections from clients and distribute the requests across target instances. The distribution of requests is usually done on layer 7 (application layer) or layer 4 (transport layer). These layers are a theoretical model that organises computer networking into 7 layers and is know as the OSI model. A separate article on computer networking will be needed to tackle that. But for now, what is important to know is that most load balancers can work on the application layer or transport layer, meaning that they work with layer 7 protocols like HTTP(S) or layer 4 protocols like TCP, UDP, SMTP, SSH. The example in this section will only cover the more popular layer 7 application load balancers that work with HTTP/HTTPS.
While the low level implementation details and use cases between layer 7 and layer 4 load balancers are different, the principles remain the same. Load balancers are used to distribute incoming traffic across a number of target instances
The distribution of the requests among the target instances typically uses a round robin algorithm where requests are sent to each instance sequentially. So, request #1 goes to instance #1, request #2 to instance #2, request #3 to instance #3, request #4 again comes to instance #1 and so on. While other balancing algorithms exist, the round robin algorithm is the most popular one used by most cloud providers for load balancing.

The diagram above is a logical depiction of how load balancers work. It only shows one load balancer, which is not a very resilient design. This logical abstraction is easy to illustrate, but is not accurate.
Behind the scenes, multiple load balancer nodes are deployed into each subnet within an availability zone. The load balancer is created with a single DNS record that points at all the elastic load balancer nodes created, i.e. this single DNS record points at all of the IP addresses of the actual nodes deployed. All incoming requests are distributed equally across all the load balancer nodes and the load balancer nodes in turn equally distribute requests to target instances. In this way, you don’t have a single point of failure.
A more realistic, albeit more complex, representation of how load balancers work is shown below. In this example, requests will come to any of the load balancer nodes deployed across the three subnets and then they are equally distributed across the target instances.

Why use it
Load balancers ensure that traffic is distributed among the target instances. This spreads out the load and prevents a single instance from being overloaded with an excessive number of requests.
Load balancers also create a loosely coupled architecture. Loose coupling is generally sought because it prevents the need for users to be aware of the instances, or instances to be aware of other instances.
What exactly does being “aware” mean? Since user requests are first sent to the load balancer, users are not aware of the instances actually responding to their request. All communication is done via the load balancer, so it becomes easy to change the type and number of instances without the user being aware of it. The load balancer is aware of the instances in its target so it can send the request to all relevant instances.
Bringing it Together - Load Balancing & Auto Scaling in Action
The diagram below shows load balancing and auto scaling used for a three tiered web application consisting of a web, application and database tiers. Each of these tiers have separate instances/infrastructure.
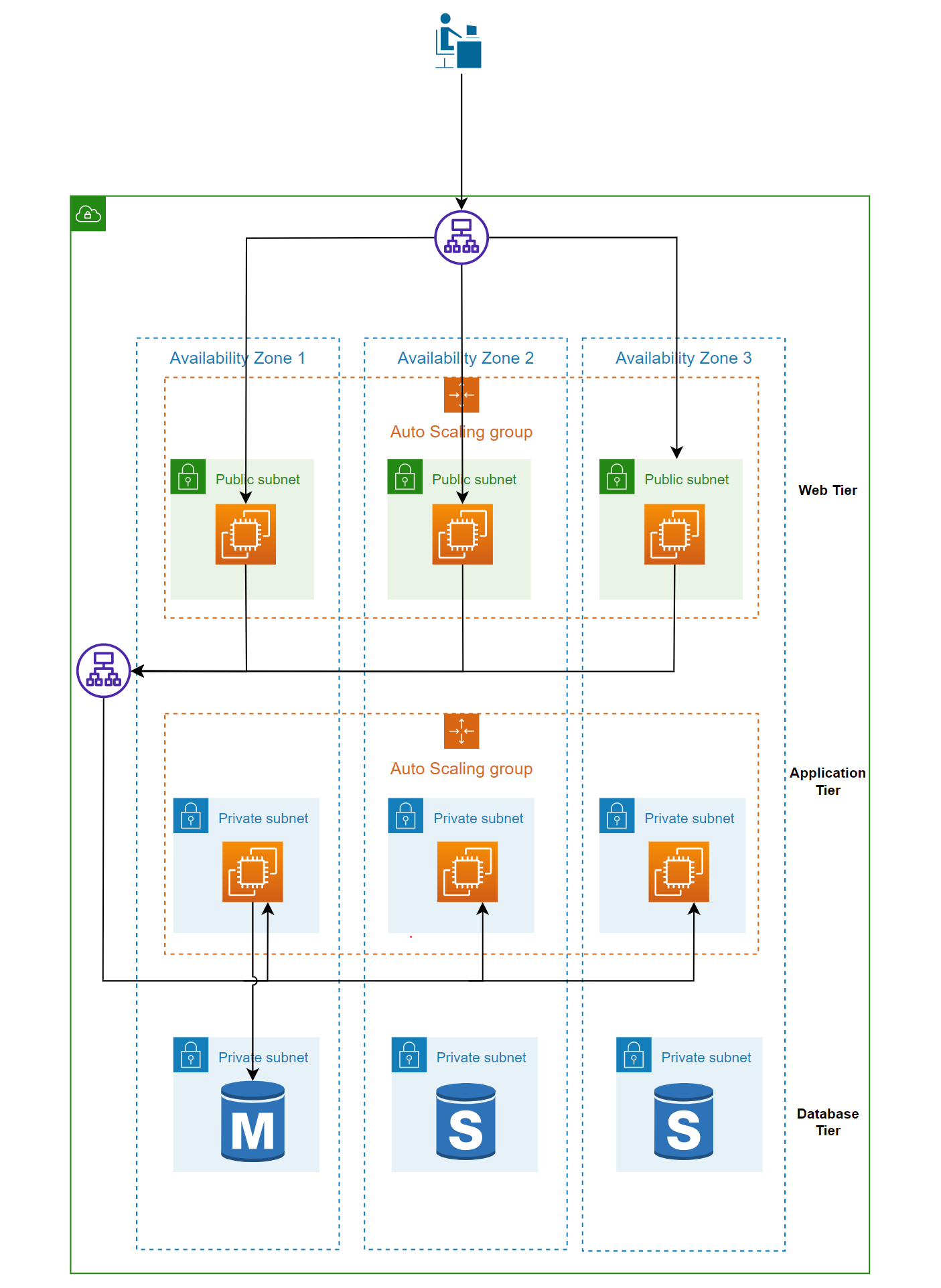
The instances in the web and application tiers are in separate auto scaling groups. There is also a load balancer between the user and the web tier, and between the web tier and the application tier.
By having a load balancer between the user and the web tier, the web tier can scale independently, using the auto scaling feature to add more or remove instances as needed. The user does not need to know which instance to connect to as the connection is through a load balancer. This is loose coupling in action. The same logic applies between the web tier and application tier. Without the load balancer, the instances in the two tiers would be tightly coupled, making scaling difficult.
The database tier in this case is an RDS database with one master and two standby nodes. All reads and writes go to the master node and if this node fails, there is an automatic failover to one of the standby instances.
To conclude, auto scaling and load balancing are often used together.
Auto scaling ensures:
Resilience - as it can automatically and immediately increase the number of instances in response to growing demand. It can also self heal, so even if you don’t anticipate the need for immediate and automatic scaling based on changes to demand, self healing is almost always desired as it increases the availability of your architecture
Cost control - ability to scale in and reduce the number of instances used during periods of lower demand can save you money
Load balancing ensures:
Distribution of load - prevents a single node being overloaded with requests
Loose coupling - removes the need for awareness between users and instances, and between instances themselves. This allows for instances to scale independently